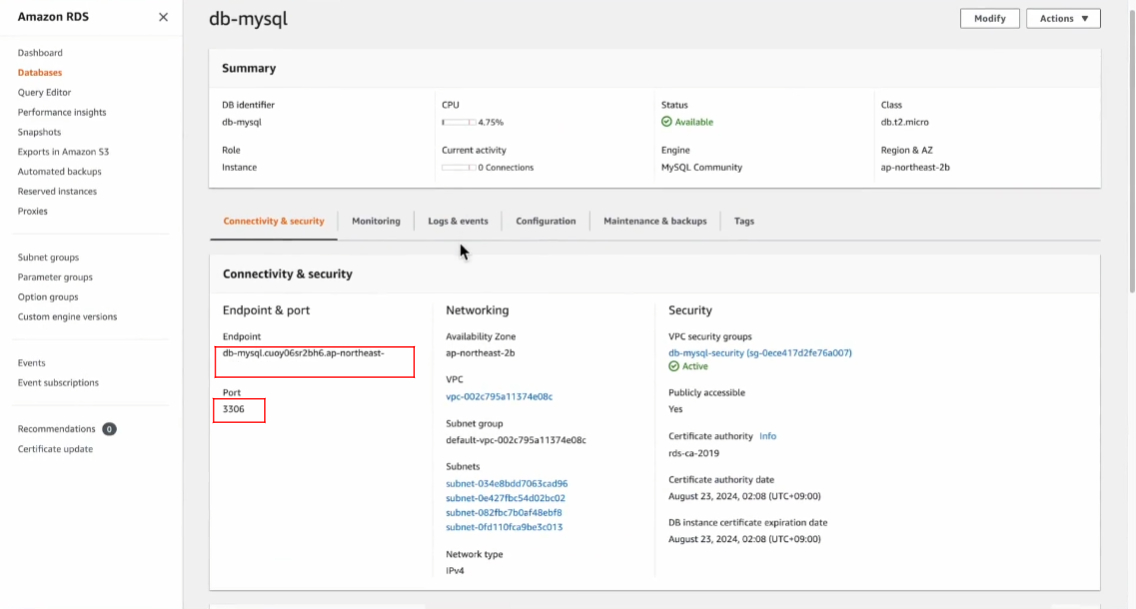
DNS란?
DNS란 Domain Name System의 약어로, 인터넷에서 사용되는 컴퓨터나 기기들의 주소를 인터넷 사용자가 쉽게 이해하고 기억할 수 있는 도메인 이름(예: www.google.com/) 변환해주는 시스템입니다.
DNS는 인터넷에서 매우 중요한 역할을 하며, 인터넷 사용자가 웹 사이트를 방문하거나 이메일을 보내는 등의 모든 인터넷 활동에서 사용됩니다.
DNS 작동

브라우저(PC) → local DNS(ip를 제공해주는 업체 isp 인터넷 서비스프로바이더 _ex. 통신사) → DNS 서비스 순으로 동작합니다. DNS 서비스는 계층적으로 구성된 분산 시스템으로 이루어져 있으며, 이 계층 구조에서는 Root DNS Server, TLD DNS Server, SLD DNS Server가 각각의 역할을 수행합니다.
1. Root DNS 서버
인터넷에서 최상위에 위치하며 모든 요청이 이 서버를 거쳐야 한다. TLD(Top-Level Domain) DNS Server에 마지막 주소(ex. com, io 등)를 알려준다.
2. TLD DNS 서버
도메인 이름의 최상위 레벨을 관리(ex. com, io등)한다. 모든 도메인 이름은 하나 이상의 TLD에 속하며, SLD DNS 서버에 도메인 이름(ex. naver, google)을 알려준다.
3. SLD DNS 서버
도메인의 중간 레벨을 관리(ex. naver, google)한다. 도메인 이름에 대한 IP 를 반환한다.
주소를 요청하면 많은 통신이 일어나므로 매번 주소를 요청하는 것은 비효율적입니다. 이 때문에 주소를 한 번 알아내면 캐싱(PC나 local DNS에 주소를 저장)이 일어나게 됩니다.
❓ 그렇다면 캐싱을 얼마나 오래 가지고 있을까요?
TTL (Time to Live)
DNS 레코드가 캐싱될 수 있는 최대 시간을 나타내는 값입니다. TTL이 높을수록 DNS 레코드가 캐싱될 수 있는 시간이 더 길어지므로, 캐시 효율성은 높아집니다. 일반적으로, TTL은 분에서 시간 단위로 설정됩니다.
IPv4와 IPv6
- IPv4와 IPv6는 인터넷 프로토콜 주소 체계입니다.
- IPv4는 32비트로 구성된 주소 체계로, 최대 약 43억개의 IP 주소를 사용할 수 있습니다.
- 인터넷 사용자의 증가로 인해 IPv4 주소가 부족해지는 문제가 발생했습니다.
- IPv6가 등장하게 되었습니다.
- IPv6는 128비트로 구성된 주소 체계로, 약 340경개의 IP 주소를 사용할 수 있습니다.
- 주소 고갈 문제를 해결할 수 있을 뿐만 아니라, 보안성과 기능 면에서도 개선되었습니다.
IPv4 예시) 192.168.0.1.
IPv6 예시) 2001:0db8:85a3:0000:0000:8a2e:0370:7334
레코드 타입
DNS 레코드 타입은 다음과 같습니다.
- A 레코드: 호스트네임(도메인 네임)과 IPv4 주소를 연결합니다.
- AAAA 레코드: 호스트네임과 IPv6 주소를 연결합니다.
- CNAME 레코드: 호스트네임을 다른 호스트네임과 연결합니다. 다른 호스트네임은 반드시 A 혹은 AAAA 레코드가 있어야 합니다.
- NS 레코드: 호스트존의 네임서버(DNS 서버)를 지정합니다.
호스트존은 주소록입니다. public 호스트존은 도메인 네임의 IP 주소를 가리키며, private 호스트존은 사설망 내부에서 사용됩니다. 또한, SOA 레코드는 메타 데이터를, NS 레코드는 네임서버 정보를 담고 있습니다.
CNAME vs Alias
| CNAME | Alias |
| DNS 레코드의 유형 호스트 이름을 다른 호스트 이름에 매핑하는 데 사용 |
|
| 호스트 이름을 다른 호스트 이름으로 매핑 | 퍼블릭 IPv4 DNS랑 연결 |
| 호스트 이름이 변경되었거나 호스트 이름이 서로 다른 IP 주소를 가리키도록 하려는 경우에 유용 | 호스트 이름을 Amazon S3 버킷, Elastic Load Balancer 또는 Amazon CloudFront 분산 된 웹 사이트와 같은 AWS 리소스에 매핑 |
| CNAME은 루트 도메인이 아닌경우에만 적용가능 (ex app.mydomain.com O, mydomain.com X) |
AWS 리소스에 대한 DNS 레코드를 만들 수 있음 (Amazon Route 53에서만 지원) |
Route53
TLD DNS, SLD DNS 서버 두 개의 역할을 동시에 한다.
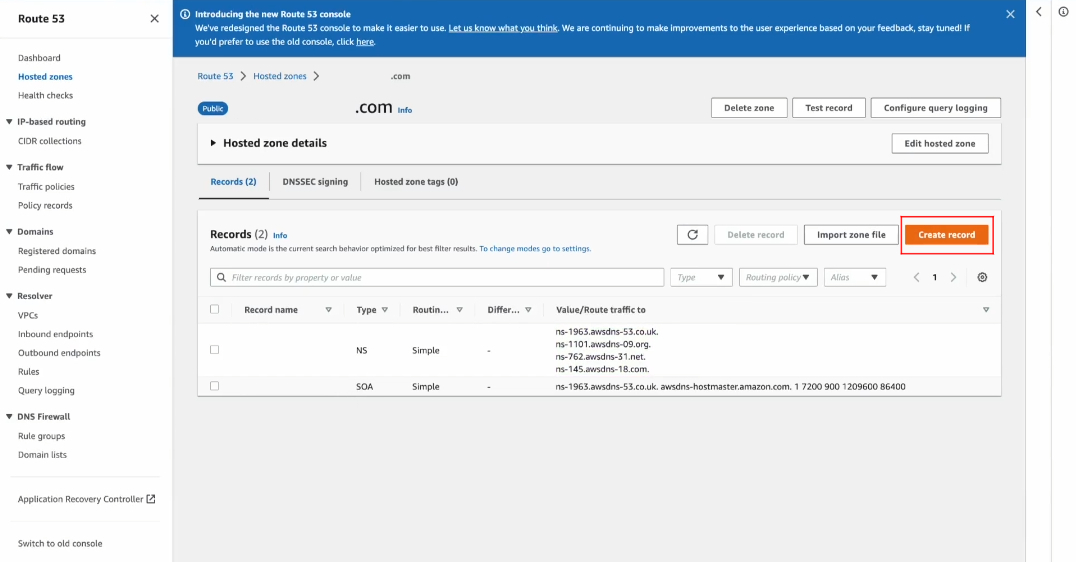
- 도메인을 구매했다면 서버가 다운되거나 에러가 있을 때를 대비하여, NS(네임 서버)에 4개가 생성되어 있다.
- SOA 메타데이터가 담겨있다.
CNAME 적용하기


Alias 적용하기

# 도메인으로 IP주소 확인하기
nslookup ctest.도메인.com
※ CNAME은 서브 도메인이 필요
※ EC2 퍼블릭 IPv4 DNS로는 Alias를 사용할 수 없다.
'aws' 카테고리의 다른 글
| 08. [aws] VPC (0) | 2023.05.26 |
|---|---|
| 07. [aws] 도메인 HTTPS 연결 (0) | 2023.05.26 |
| 05.5 [aws] Sqlectron (0) | 2023.05.23 |
| 05. [aws] RDS (0) | 2023.05.14 |
| 04.5. [aws] SSL과 HTTPS (0) | 2023.05.14 |