사전 준비
머신러닝이란?
알고리즘이란?
- 💡 머신러닝에 들어가기에 앞서 알고리즘이란 수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것, 계산을 실행하기 위한 단계적 절차
- 문제 A. 시험 전 날 커피를 몇 잔 마시면, 다음 날 시험에서 몇 점을 받을 수 있을까?

정확히 말하면 딥러닝은 머신러닝 방법 중 하나입니다. 머신러닝(ML, 기계학습)이라는 포괄적인 범위 안에 딥러닝(Deep learning 심층 학습)이 포함되어 있죠. 딥러닝은 인공 신경망을 기반으로 한 특수한 머신러닝 기법으로, 주로 자연어 처리, 이미지, 비디오 분석 같은 목적으로 사용됩니다. 딥러닝은 입력층과 출력층 사이에 은닉층을 두고 작동시킨다는 특징이 있습니다.
연구 초반에는 MLP(Multi-Layer Perceptron)이라고 불렸으나 사람들의 유행을 타기 시작하면서 어감이 좋은 딥러닝으로 굳어지게 되었습니다. 요즘들어 우리가 말하는 인공지능과 머신러닝이라고 하는 것은, 여러 방법 중에서 월등하게 성능이 좋은 딥러닝을 말합니다. 최근 10년간 모든 학문 분야 중 가장 많은 연구가 이루어졌고 덕분에 파이썬이라는 언어가 덩달아 전성기를 맞게 되었죠.

머신러닝 학습 방법
- 💡 머신러닝은 크게 3가지로 분류해요. 바로 지도/비지도/강화 학습이죠. 각각의 개념과 차이점에 대해서 알아볼까요?
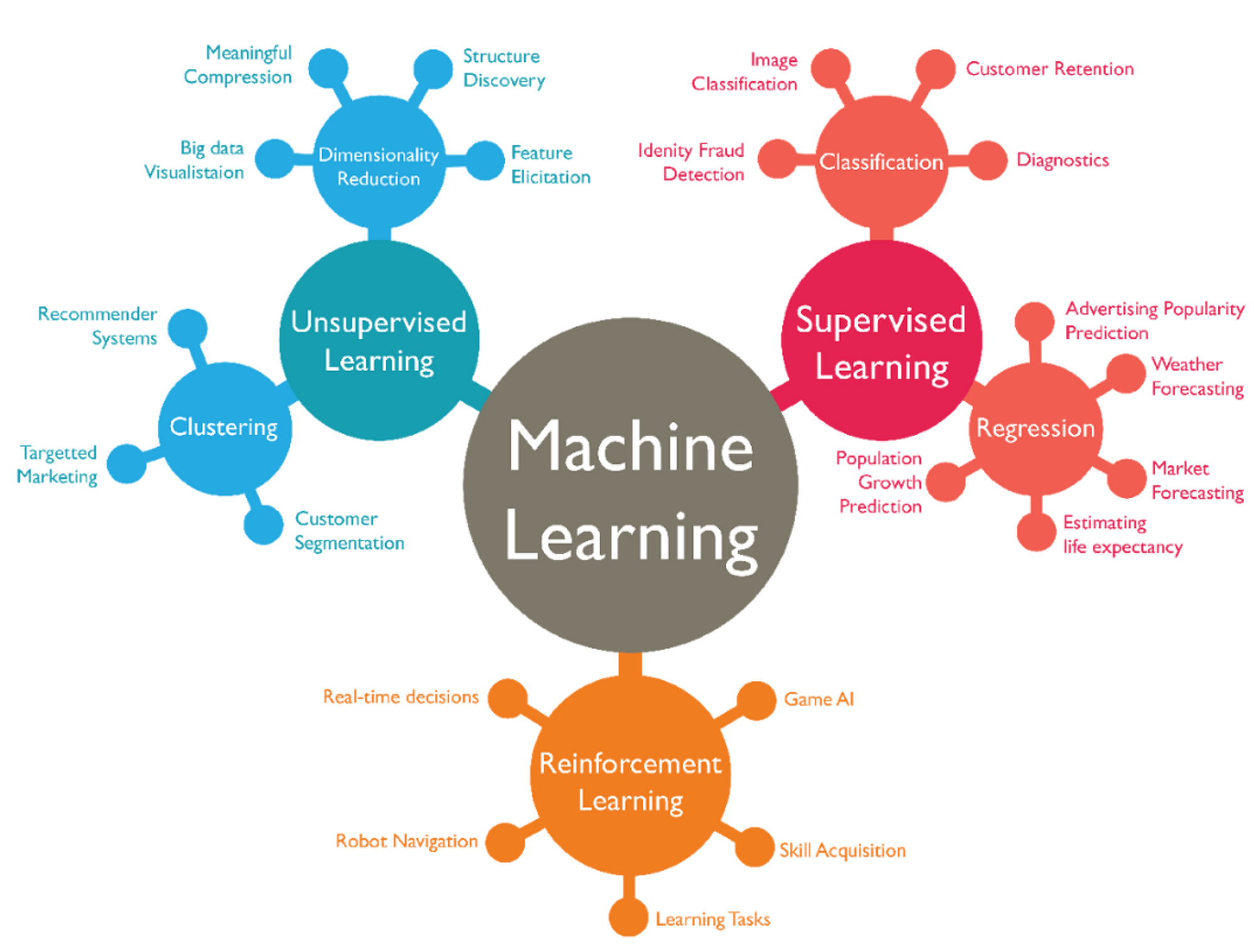
지도 학습(Supervised learning)

정답을 알려주면서 학습시키는 방법을 말합니다. 위에서 배웠던 회귀와 분류 문제가 대표적인 지도 학습에 속합니다. 지도 학습은 기계에게 입력값과 출력값을 전부 보여주면서 학습시키죠. 단, 정답(출력값)이 없으면 이 방법으로 학습시킬 수 없습니다.
여러분이 회사에서 머신러닝 엔지니어로 근무한다면 회사에서 필요로 하는 문제를 풀기 위해 많은 데이터를 필요로 할 겁니다. 근데 대부분 회사에는 데이터가 없거나 혹은 입력값에 해당하는 데이터는 있어도 출력값(정답)에 해당하는 데이터가 없는 경우가 비일비재합니다. 따라서 입력값에 정답을 하나씩 입력해주는 작업을 라벨링(Labeling, 레이블링) 또는 어노테이션(Annotation)이라고 합니다.
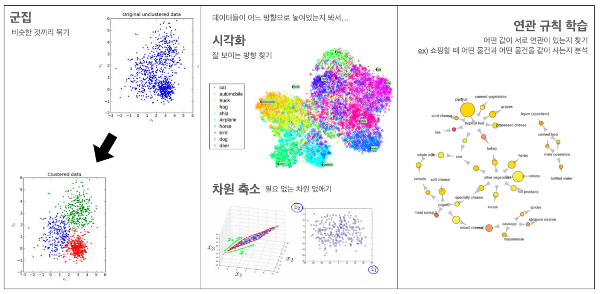
비지도 학습 (Unsupervised learning)

정답을 알려주지 않고 군집화(Clustering)하는 방법을 말합니다. 비지도 학습은 그룹핑 알고리즘(Grouping algorithm)의 성격을 띄고 있습니다. 예를 들어 음악을 분석하여 장르를 구분하는 문제를 푼다고 가정해봅시다.
❓ 음원 파일을 분석하여 장르를 팝, 락, 클래식, 댄스로 나누는 문제
우리가 가지고 있는 데이터에 입력값(음원파일)과 출력값(장르) 둘 다 존재한다면 우리는 지도 학습으로 이 문제를 풀 수 있지만 출력값에 해당하는 장르 데이터가 없을 때 비지도 학습 방법을 사용합니다. 비지도 학습 방법은 라벨(Label 또는 Class)이 없는 데이터를 가지고 문제를 풀어야 할 때 큰 힘을 발휘하죠!
☝ 우리에게는 수 백만개의 음원 파일이 있는데, 각 음원 파일에 대한 장르 데이터는 없어. 그러니까 기계에게 음원 파일을 들려주고 알아서 비슷한 것끼리 분류하게 해보자! 분류한 것에 나중에 명칭만 입력해 줄게.
강화 학습(Reinforcement learning)

주어진 데이터없이 실행과 오류를 반복하면서 학습하는 방법(알파고를 탄생시킨 머신러닝 방법!!)을 말합니다. 행동 심리학에서 나온 이론으로 분류할 수 있는 데이터가 존재하지 않거나, 데이터가 있어도 정답이 따로 정해져 있지 않고, 자신이 한 행동에 대해 보상(Reward)를 받으며 학습하는 것을 말합니다.
- 강화학습의 개념
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
게임을 예로 들면 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임 룰(Environment)에서 현재 상태(State)에서 높은 점수(Reward)를 얻는 방법을 찾아가며 행동(Action)하는 학습 방법으로 특정 학습 횟수를 초과하면 높은 점수(Reward)를 획득할 수 있는 전략이 형성되게 됩니다. 단, 행동(Action)을 위한 행동 목록(방향키, 버튼)등은 사전에 정의가 되어야 합니다.
지도학습 회귀와 분류
- 💡 머신러닝에서 문제를 풀 때, 해답을 내는 방법을 크게 회귀 또는 분류로 나눌 수 있습니다. 각각이 무엇을 의미하는지 배워봅시다!
회귀 (Regression)
❓ 사람의 얼굴 사진을 보고 몇 살인지 예측하는 문제
모든 문제를 풀기 위해서는 먼저 입력값(Input)과 출력값(Output)을 정의해야 합니다.
-
- 이 문제에서 입력값은 [얼굴 사진]이 되고 출력값은 [예측한 나이]가 됩니다.
- 나이의 값은 연속적이죠. 이런 식으로 출력값이 연속적인 소수점으로 예측하게 하도록 푸는 방법을 회귀라고 합니다.
- 이런 연속적인 문제는 보통 회귀로 푼다.
- 머신러닝에서는 보통 출력값을 소수점(float)으로 표현합니다.
분류 (Classification)
❓ 대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 이수 여부(Pass or fail)를 예측하는 문제
-
- 이 문제는 pass 와 fail 중간이 연속적이지 않으므로 분류입니다.
- 이런 분류 종류를 클래스(class)라고 합니다.
- 입력값은 [공부한 시간] 그리고 출력값은 [이수 여부]가 됩니다.
- 우리는 이수 여부를 0, 1 이라는 이진 클래스(Binary class)로 나눌 수 있습니다. 0이면 미이수(Fail), 1이면 이수(Pass) 이런식으로요. 이런 경우를 이진 분류(Binary classification)이라고 부릅니다
* 이진 클래스의 클래스는 나눈 값을 뜻합니다.
❓ 대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 성적(A, B, C, D, F)을 예측하는 문제
-
- 이 방법을 다중 분류(Multi-class classification, Multi-label classification)라고 부릅니다.
회귀와 분류 둘 다 가능한 문제
❓ 사람의 얼굴 사진을 보고 몇 살인지 예측하는 문제 (분류)
-
- 만약 나이를 범위로 쪼개어 생각하면 어떨까요?
| 나이 범위 | 클래스 |
| 0 - 9세 | 0 |
| 10 - 19세 | 1 |
| ... | |
| 90 - 99세 | 9 |
| 100 - 109세 | 10 |
머신러닝 프로세스
① 데이터 수집 → ② 데이터 전처리 → ③ 모델 학습 → ④ 모델 평가 → ⑤ 모델 베포
'머신러닝' 카테고리의 다른 글
| extra [머신러닝] 넘파이 (1) | 2023.05.19 |
|---|---|
| extra [머신러닝] 판다스 (0) | 2023.05.18 |